I Tag a Work Item. Sometimes I Come Back to a PR.
Yesterday I tagged an Azure DevOps work item analyse and went to bed. In the morning there was a draft PR against the right branch. Tests written, work item documented, code reviewed before any human looked at it. I had not touched it.
Some mornings there is no PR. There is a failed stage and a comment asking me what I want to do. Both outcomes are useful. Both happen because the work item kept moving while I was not.
I am presenting the whole thing at BC TechDays next month. This post is the map, not the talk.
The shape of it
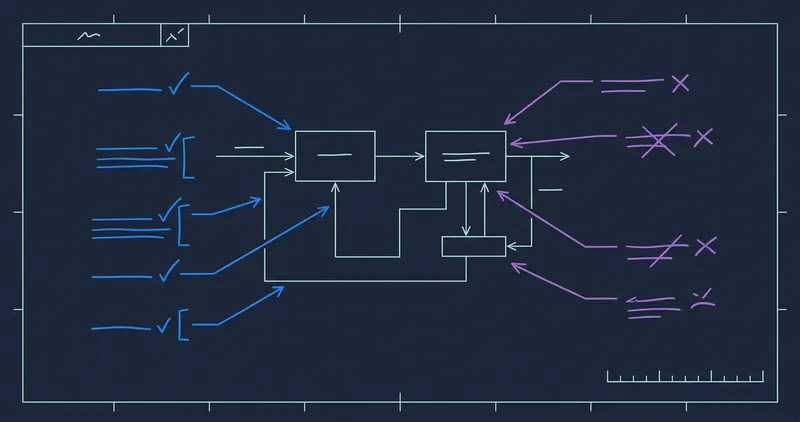
A pipeline of twelve stages. Three of them stop and wait for me. Everything else is agents talking to other agents. Keep in mind I work for an ISV, so my flow might be different from yours.

Before any of that, an analyzer agent reads the work item and decides whether it is worth starting at all. It can pull in the Zendesk ticket the description points at. It can pull in the build log from the failing CI run if the work item is about a compiler warning. It searches the target repo to make sure the object the work item describes actually exists where it says. If something is missing it tries to answer the question itself before bouncing the work item back to me. Three verdicts: proceed, needs-input, reject. It is the cheapest agent in the pipeline and the one I trust most, because all it does is read.
The first time I see anything is the plan. The planner writes test scenarios first, one for every acceptance criterion, and only then describes the production change those tests will drive. Tests before code, spec before tests. (TDD and SDD stacked on top of each other, if you want the labels.) A reviewer argues with the plan until it signs off or they run out of budget. Then it lands as a comment on the work item. I read it. If it is roughly the shape I wanted, I tag plan-approved and walk away again. If it isn’t, I write back what is off and let them have another go.
The second time I see anything is a draft PR. The code is already written. The pipeline’s reviewer signed off. CI built it. The loop bounced it back until reviewer and CI agreed. It is a draft on purpose. I want to look at it before it goes out to a human PR review (yes, we still do those). So one of our custom environments has been spun up and the change has been added, so I can both checkout the code and go inside BC and see it. If it looks right, I remove the draft flag and let the team review it like any other PR. If something is off, I drop a /fix comment with the thing that is broken and the coding loop picks up where it left off.
The third time I see anything is after ADO auto-merges it. A watcher notices and the rest carries on without me. A documenter updates the work item with additional info and updates release notes, and if the task warrants it another agent drafts pages for the doc site.
Everything runs in Docker. State lives in a database. If a stage dies I can resume from where it fell over without rerunning the rest. (I have needed that more than once during development.)
Four things that I learned while building it
Reviewers do not review. They delegate. The plan reviewer spawns four specialists in parallel. The code reviewer spawns eight. My first version was one big reviewer with one long prompt and it kept signing off on plans that fell over in the coding loop. Splitting the review into focused specialists, each with one narrow brief, fixed most of that. It still misses things. They are just weirder.

The LSP is the difference. The agents navigate AL through documentSymbol, findReferences, and hover. They follow the code the way the compiler sees it, not the way grep does. Getting my AL LSP to run inside a container next to each agent took longer than I want to admit. It is the line between “AI that sometimes guesses the right object” and “AI that knows what your codeunit actually calls.” I will not run one of these without it again.
The devils-advocate broke my pipeline. It is one of the specialist reviewers I have and its job is to question the plan. It questioned everything. Every loop, a new concern. The coder revised. The reviewer ran again. New concern. Repeat until I ran out of budget.
The fix felt wrong while I wrote it. After two consecutive loops where the devils-advocate is the only specialist still blocking, it gets demoted to advisory for the rest of the run. Its findings still go in the log. The vote does not count. Felt dirty. Works. I am still tweaking its prompts so it asks the right questions without being the thing that derails the train.
Telling the agent to use the LSP is harder than getting the LSP to work. Having the tool available does not mean the model will reach for it. Left alone, Claude Code grabs grep and glob first every time, even when LSP findReferences would answer the same question in milliseconds without matching the symbol’s name inside comments and strings. I tried writing the rule into the agent prompt. Helped a little. I tried a separate rules file. A little more. What actually moved the needle was patching Claude Code itself so the descriptions of grep and glob the agent reads carry an extra line: “for AL code, prefer LSP.” Cheating. Works. Hoping Claude Code closes the gap at some point.
What I am not showing you (today)
The prompts. Each agent has its own CLAUDE.md and its own toolset, and the shape of those prompts is most of the actual work. The coder gets bash, git, and the LSP. The analyzer can only read. I have spent just as much time tuning them as writing the orchestrator.
Cost. Not all stages are equal, and not all of them need Opus. I expected the coder to be the one that needed the biggest model. It does not. redacted was good enough at writing AL once I handed it the right tools and the right prompt, and that single swap is the reason the math works.
Processing time. I am not the one waiting. While it runs I am writing other code, in meetings, fetching coffee, on the floor with my kid, or asleep. The pipeline does not stop when I do.
Come to the talk
BC TechDays, next month. The slot is 90 minutes and this pipeline is not the only thing we are bringing, so no end-to-end live run on stage. What I will show is the parts that actually do the work. The planning loops, the reviewer arguments, the logs.
And maybe, just maybe even a repo link if all is approved for release.